
A central piece in enabling intelligent agentic behavior in foundation models is to make them capable of introspecting upon their behavior, reasoning, and correcting their mistakes as more computation or interaction is available. Even the strongest proprietary large language models (LLMs) do not quite exhibit the ability of continually improving their responses sequentially, even in scenarios where they are explicitly told that they are making a mistake. In this paper, we develop RISE: Recursive IntroSpEction, an approach for fine-tuning LLMs to introduce this capability, despite prior work hypothesizing that this capability may not be possible to attain. Our approach prescribes an iterative fine-tuning procedure, which attempts to teach the model how to alter its response after having executed previously unsuccessful attempts to solve a hard test-time problem, with optionally additional environment feedback. RISE poses fine-tuning for a single-turn prompt as solving a multi-turn Markov decision process (MDP), where the initial state is the prompt. Inspired by principles in online imitation learning and reinforcement learning, we propose strategies for multi-turn data collection and training so as to imbue an LLM with the capability to recursively detect and correct its previous mistakes in subsequent iterations. Our experiments show that RISE enables Llama2, Llama3, and Mistral models to improve themselves with more turns on math reasoning tasks, outperforming several single-turn strategies given an equal amount of inference-time computation. We also find that RISE scales well, often attaining larger benefits with more capable models. Our analysis shows that RISE makes meaningful improvements to responses to arrive at the correct solution for challenging prompts, without disrupting one-turn abilities as a result of expressing more complex distributions.
RISE uses supervision on an answer from a teacher to teach a small model how to improve its own responses by using additional tokens, without any external input. In this sense, the model is able to "introspect" within itself.
To develop RISE, we will start with converting a problem into a multi-turn MDP, then collect data, and finally run offline reward-weighted supervised learning in this multi-turn MDP to induce this capability.
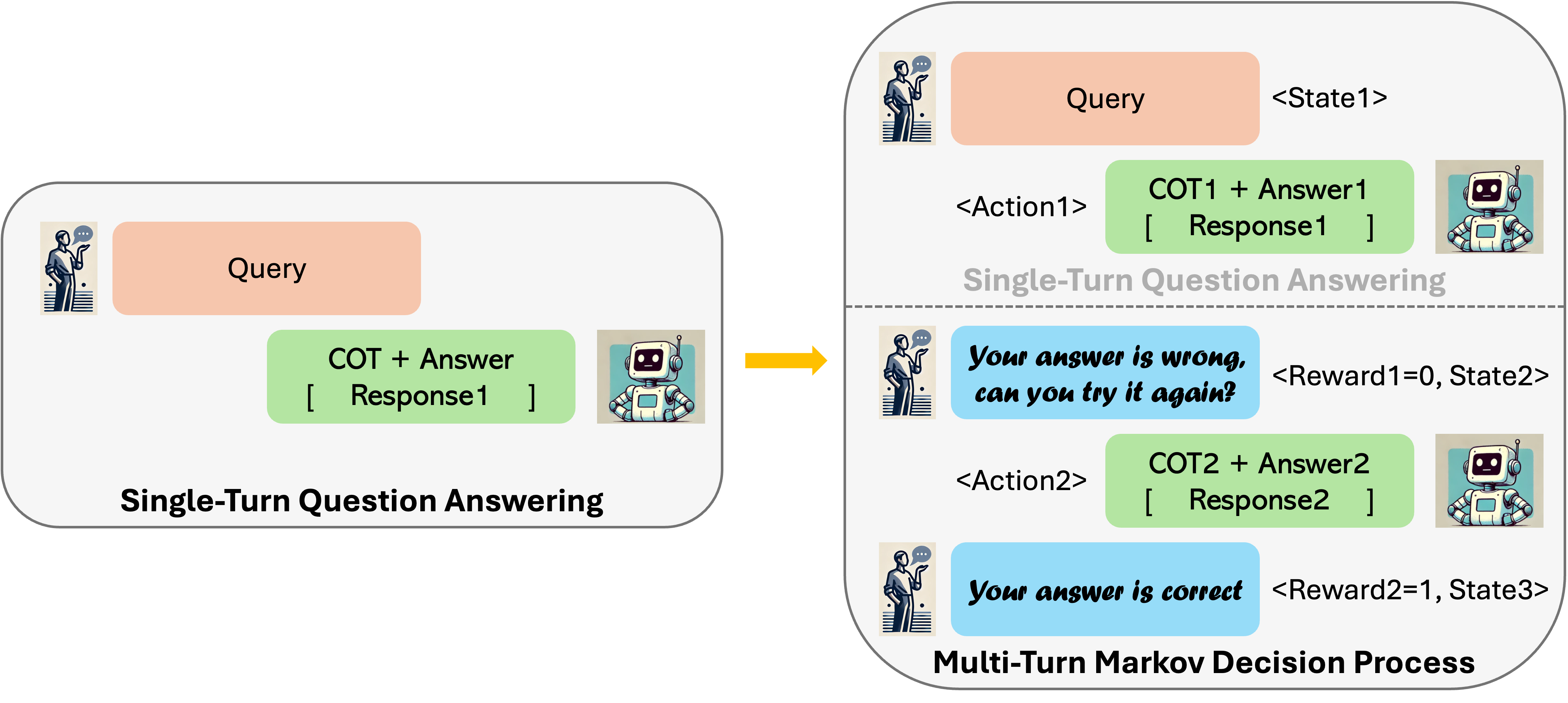
We convert single-turn problems into multi-turn MDPs. The state is given by the prompt, history of prior attempts, and optional feedback from the environment. An action is a response generated from the LLM given the state of multi-turn interaction so far.
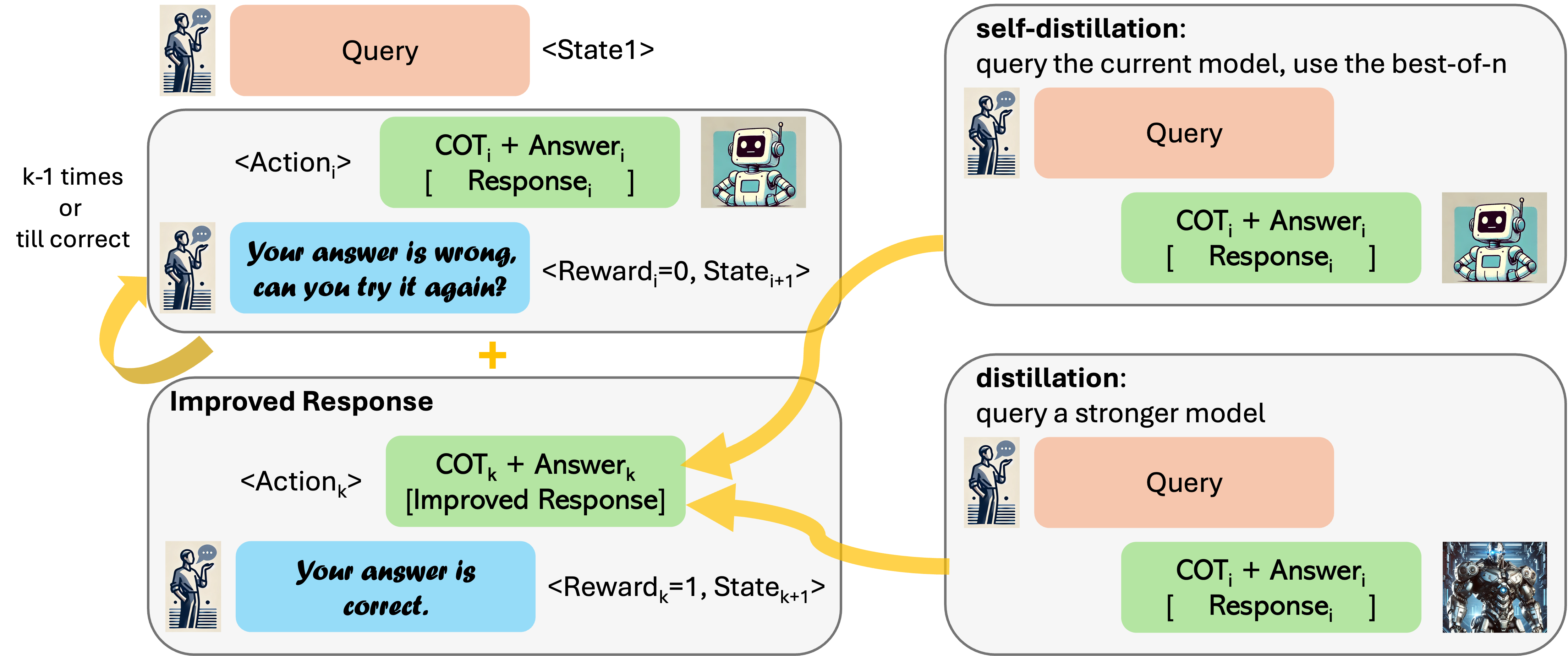
We collect data by unrolling the current model k − 1 times followed by an improved version of the response, which is obtained by
With the aforementioned data construction schemes, we perform a weighted supervised regression, where the weights are given by the exponential transformation of the reward values.
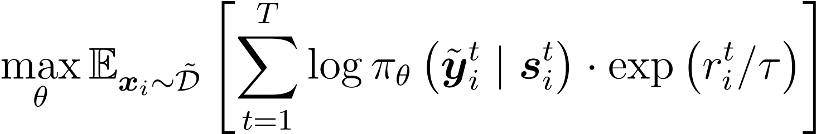
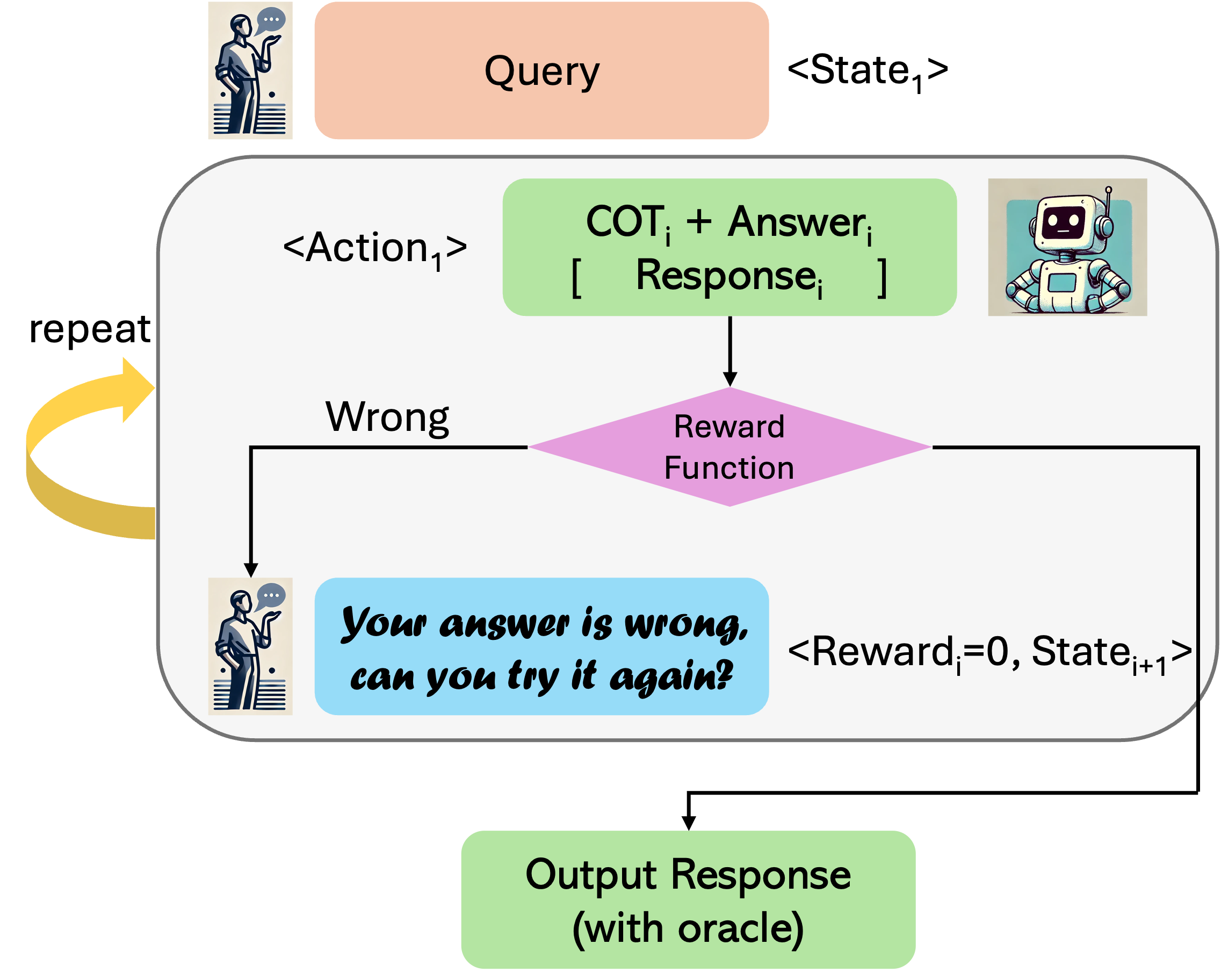
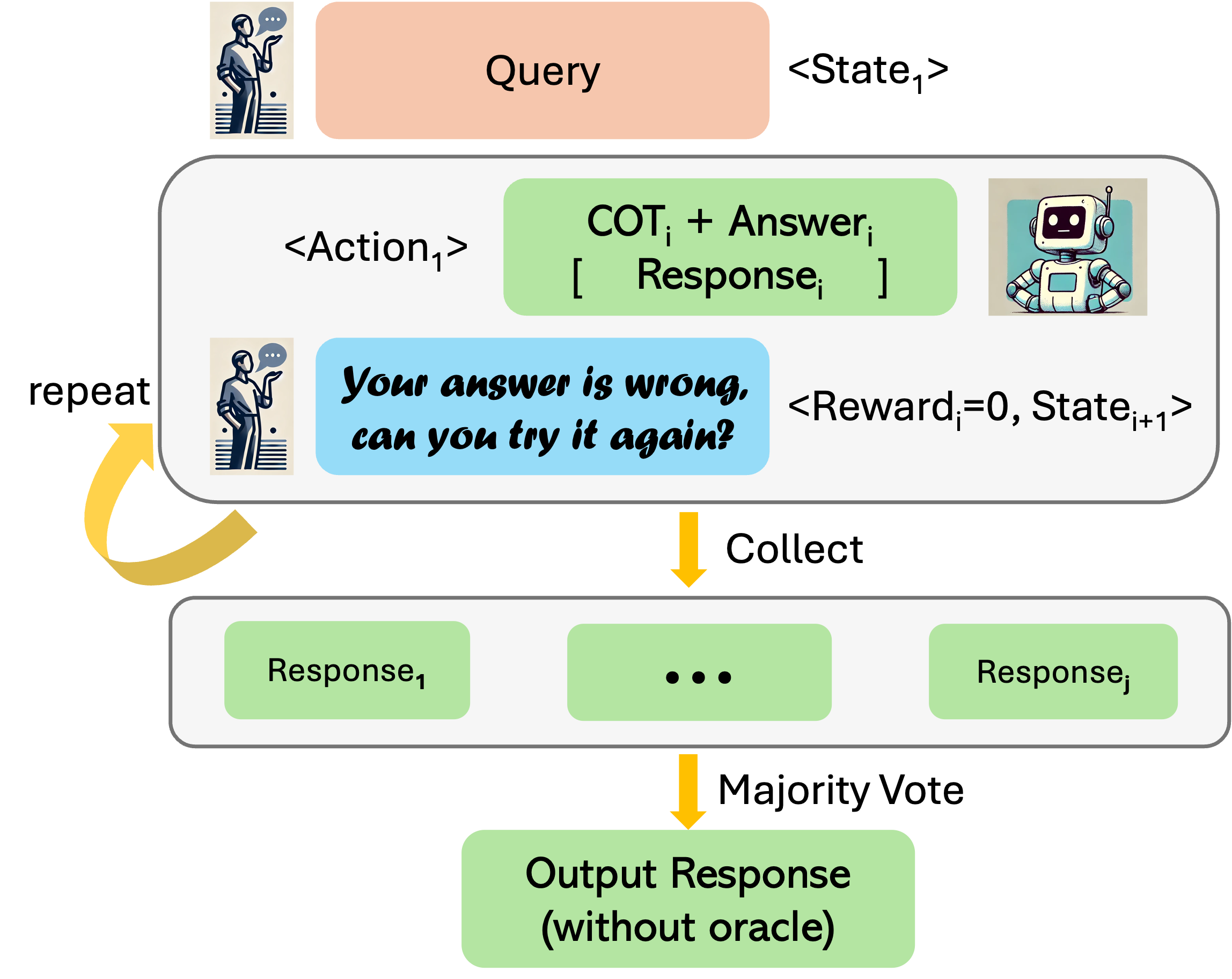
There are two ways to query the model trained via RISE upon inference
Iteratively teaching a model how to make updates on a given response can be crucial when representing the target distribution requires more capacity than what the model affords by conditioning on only the input prompt tokens. When the target distribution requires greater capacity, learning a sequence of conditionals, followed by marginalization is expected to induce a more flexible marginal distribution. This hypothesis is akin to the difference between diffusion models and variational autoencoders (VAEs) in image generation: iteratively fitting a sequence of generative distributions over intermediate noisy inputs in a diffusion model gives rise to a more flexible distribution than monolithic variational auto-encoding, even though diffusion models still utilize an evidence lower-bound objective(ELBO). While the diffusion process utilizes hand-designed noise schedules, RISE utilizes the base model itself to induce iterative improvements.
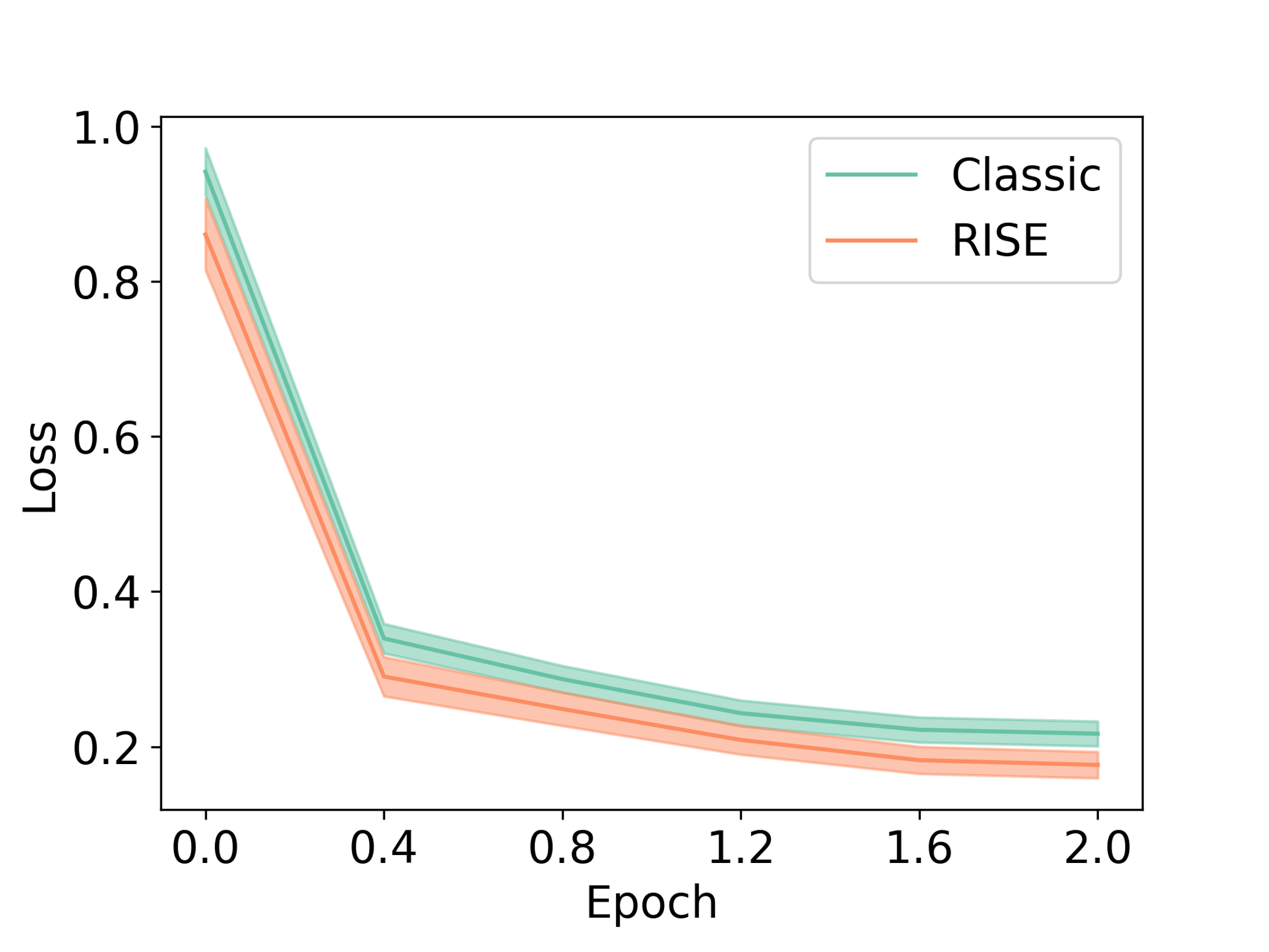
To verify if this hypothesis is true, we tracked the training un-weighted, negative log-likelihood loss (NLL) values for the oracle response given the input prompt marginalized over intermediate steps in a multi-turn rollout, and compared it against the NLL values attained by directly attempting to predict the final response (labeled as “Classic”). We find that for any given number of epochs (including fractional number of epochs on the x-axis), the NLL value is lower when conditioning on multi-turn data that RISE generates in comparison with oracle responses to the prompts obtained from an expert. This suggests that RISE is able to utilize the computation of tokens from previous turns to model the target distribution.
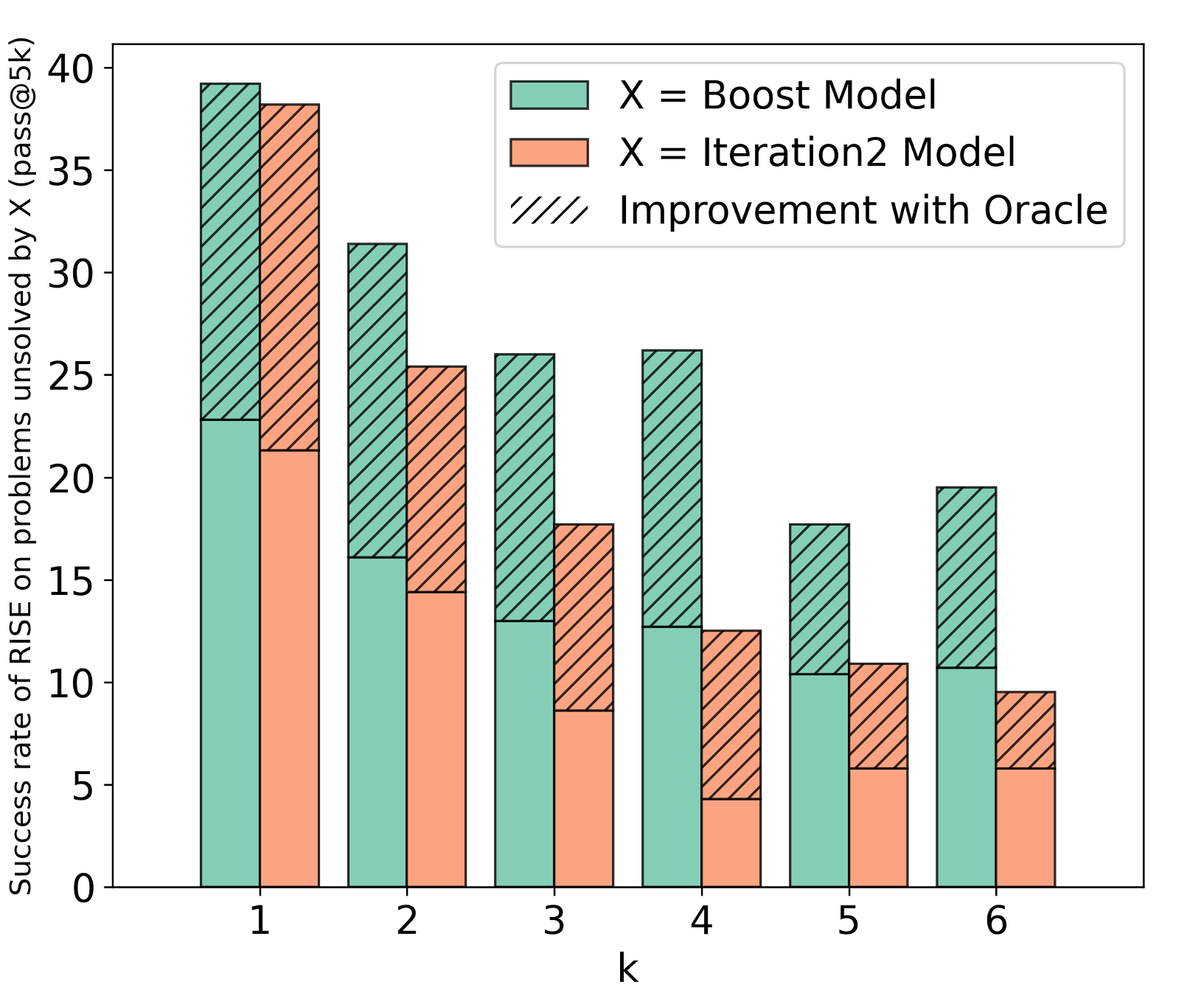
We also show that the sequential procedure learned by RISE can even solve a significant fraction of problems that were unsolved by pass@B for much larger B in the first turn, indicating that it learns to index into the pre-trained knowledge of the model in a different manner as opposed to simply translating the pass@K performance into the pass@1 performance of the model, that majority of single-turn approaches are believed to be doing.
The goal of our experiments is to demonstrate the efficacy of RISE in instilling language models with the ability to self-improve their responses over turns. Our experiments answer the following questions:
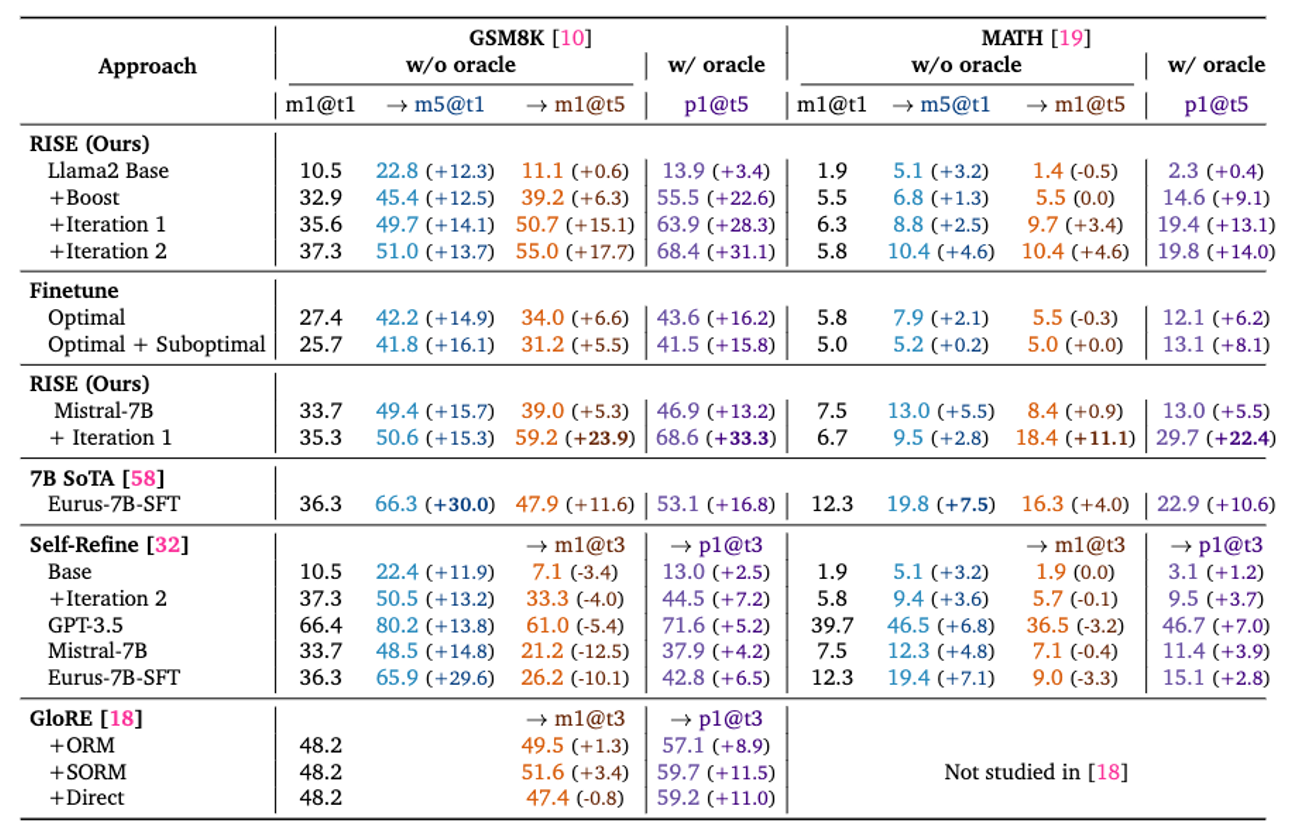
Observe that RISE attains the biggest performance improvement (in brown) between 1-turn (m5@t1) and 5-turn (m1@t5) performance w/o an oracle on both GSM8K and MATH. This performance gap is even larger when oracle early termination is allowed (p1@t5 w/ oracle). Self-Refine degrades performance across the board when used without an oracle, and attains minor performance improvements when used with an oracle. GLoRE trains a separate refinement model, but still performs worse than RISE. Using RISE on top of a better base model (Mistral-7B) is also effective (positive improvements with multiple turns), and note the m1@t5 performance of Mistral-7B exceeds even state-of-the-art math models such as Eurus-7B-SFT. Simply running single-turn SFT on data utilized by RISE is not effective at inducing a self-improvement capability, implying that the algorithmic design choices in RISE are crucial for performance. Color coding indicates numbers that can be compared to each other.
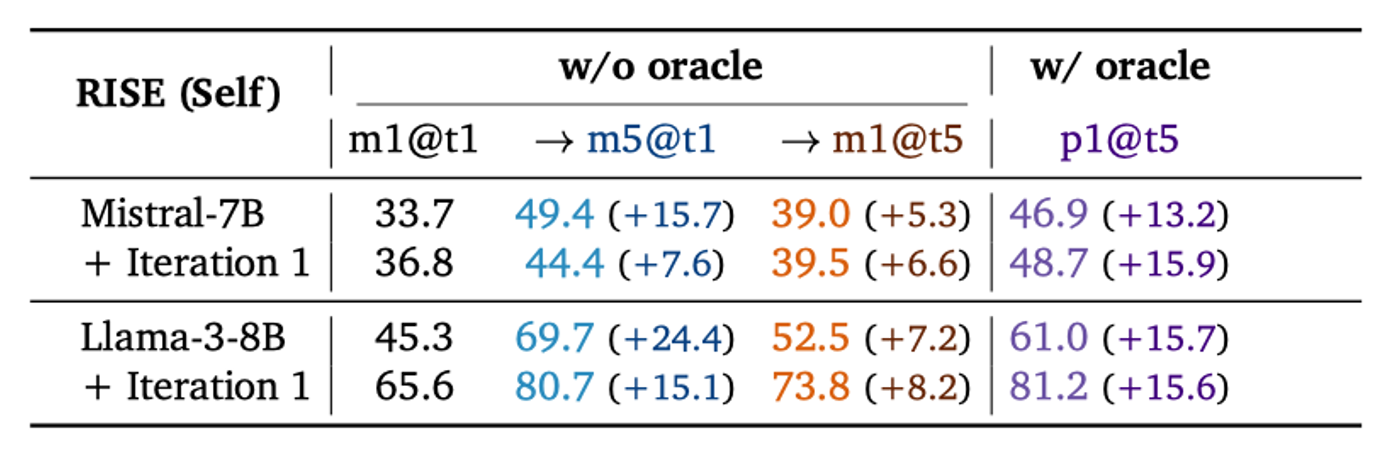
RISE is able to improve 5-turn maj@1 performance of the model with entirely self-generated data and supervision, despite the fact that the base Mistral-7B model does not produce correct answers for several problems.
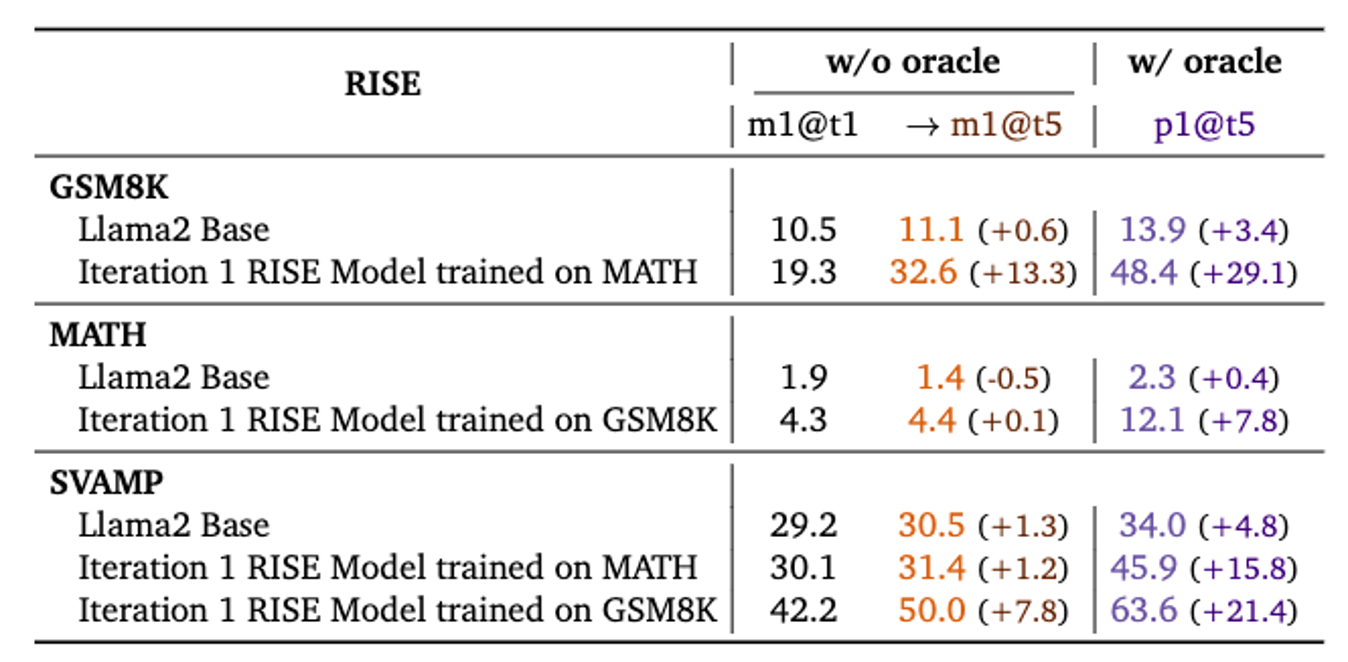
We evaluate model fine-tuned on MATH on the GSM8K test set; model fine-tuned GSM8K on MATH; and the model fine-tuned on a mixture of GSM8K and MATH on the SVAMP data. Observe even though we train on OOD prompts, RISE can still improve sequential performance.
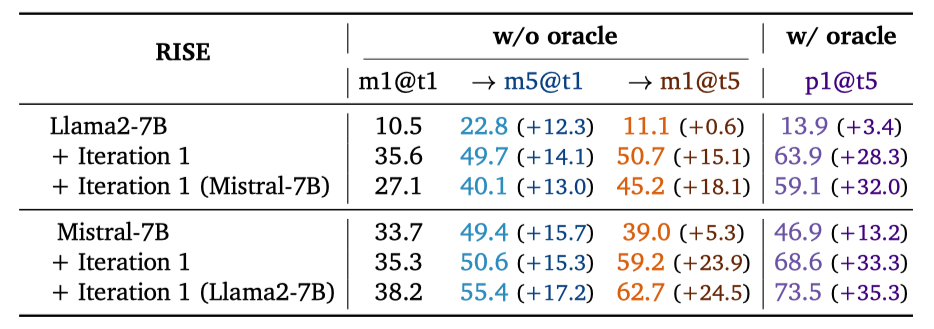
Comparing performance of RISE when training on rollouts generated by Llama2-7B vs Mistral-7B. Note that training the Mistral-7B model on rollouts generated by the weaker Llama2-7B with RISE improves performance compared to using data generated by the Mistral-7B model itself. However, the reverse is not true: training the Llama2 model on Mistral’s mistakes leads to worse performance, likely because errors from the Mistral-7B model are harder to comprehend for a worse base model.
Examples of RISE correct its previous behavior in different modes. Some only make changes to a small part (small edits), some may directly rewrite most of its previous answers (big edits) because the first step in the previous answer is wrong. The mistaken steps of different turns are highlighted in red, and the correct are highlighted in green. This demonstrates shows how RISE can correct its previous answers and finally get to a correct answer.


misc{qu2024recursiveintrospectionteachinglanguage,
title={Recursive Introspection: Teaching Language Model Agents How to Self-Improve},
author={Yuxiao Qu and Tianjun Zhang and Naman Garg and Aviral Kumar},
year={2024},
eprint={2407.18219},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2407.18219},
}